
Inference Engines: how generative AI is changing computers again
Understand how the operating system is failing us, and what the next generation of compute looks like

Download the whitepaper
About the whitepaper
Generative AI did not just introduce new applications. It exposed a structural weakness in how computers are organized. The systems we use today were designed for short-lived, deterministic tasks: open a file, run a query, render a page, exit. Modern AI workloads are the opposite. They are long-running, stateful, probabilistic, and memory-dense. The friction between these two worlds is what gives rise to inference engines.
This paper argues that the next generation of computing will be defined less by number of tensor cores and more by how systems manage model execution, memory locality, and probabilistic generation as core principles. Inference stops being an application concern and becomes a force that influences hardware design, operating systems, developer tooling, and ultimately business value itself.
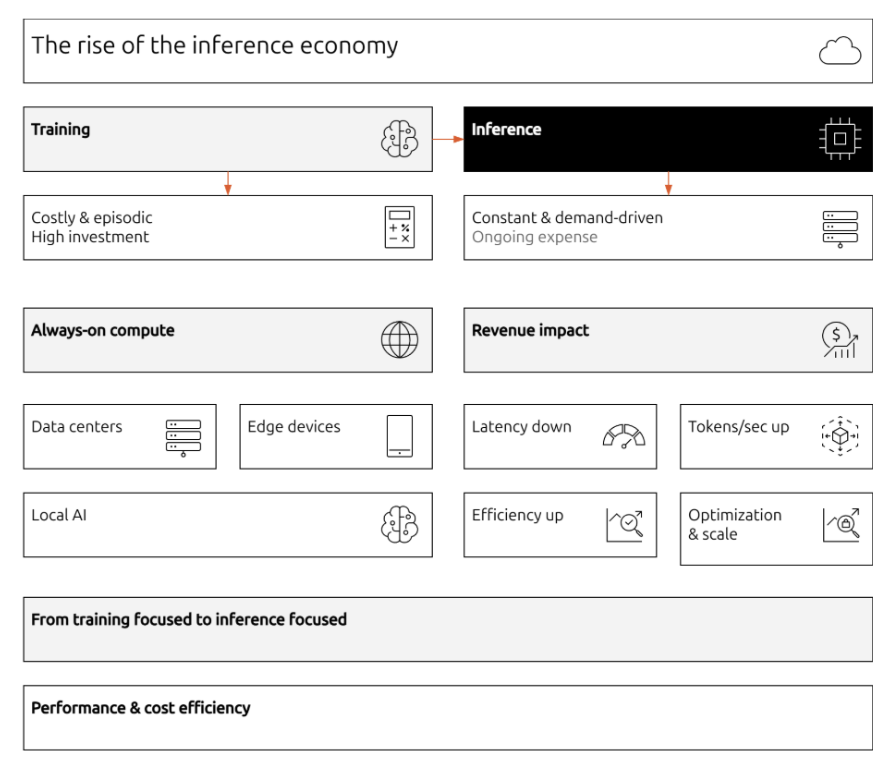
The whitepaper provides a deeper technical and architectural exploration of inference engines and how to build the next generation of AI infrastructure.
Download the whitepaper to explore:
- What defines an inference stack
- How AI inference works: a high-resolution view
- The OS bottleneck: why legacy kernels fail AI
- Core techniques in inference engines
- Introduction to inference snaps
- Business value of the optimized stack
Read more about inference snaps in the documentation.
In case of any questions, please reach out to our team.